
An alternate history of social media
I joined Rabble on the Revolution.Social podcast.
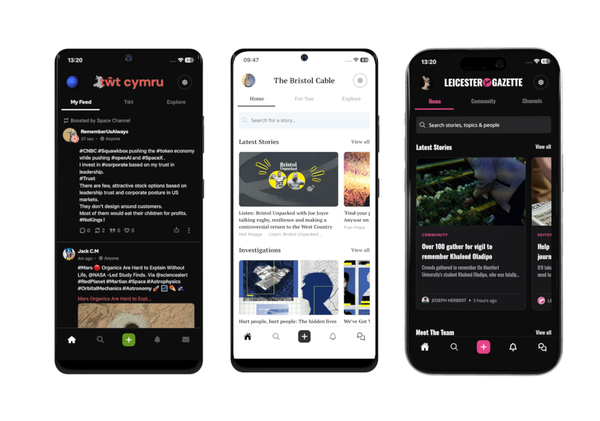
A new white paper about building open communities for news.

What resource-constrained teams need to ask before writing a line of code

AI coding works now. Here's how to think about it.
I joined Rabble on the Revolution.Social podcast.
What resource-constrained teams need to ask before writing a line of code
AI coding works now. Here's how to think about it.

A Supreme Court case about a bank robbery could redefine your digital rights.

They came for the newsroom. It was ready.

Building a community means looking beyond coding tests.
Ben Werdmuller explores the intersection of technology, democracy, and society. Always independently published, reader-supported, and free to read.
Bluesky's new service isn't about AI; it's about accessibility.
By treating source materials as contraband, the DOJ is putting both journalism and democracy at risk.
Want to report your friends and neighbors for extrajudicial kidnapping? The new White House app wants you to get in touch.

Progress on the open social web; not so much in the world.
Newsrooms have been slow to care about the open social web - but one of their most important support organizations is paying attention.
"If you want stronger decisions, make space for every voice." This is a simple technique to do this in your meetings that really works.
The implications of this case could include the effective end of Section 230 protections – and a new wave of attacks on places where people learn, share, and connect online.
John O'Nolan built a CLI for his own product - and found himself using it in an entirely new way. The underlying trend here is really exciting.
"Our home planet is struggling with a record energy imbalance, which is warming oceans to unprecedented levels, making weather more extreme and threatening health and food supplies." How we react matters.
"The materialist response isn't to reject the new technology. It's to evolve our licenses to encompass it."
"Software for humans of indeterminate age. We don't know how old you are. We don't want to know. We are legally required to ask. We won't." Open source activism at its finest.
"Teams from Google and leading universities found that large-language models change the voice, tone and intended meaning of human authors."